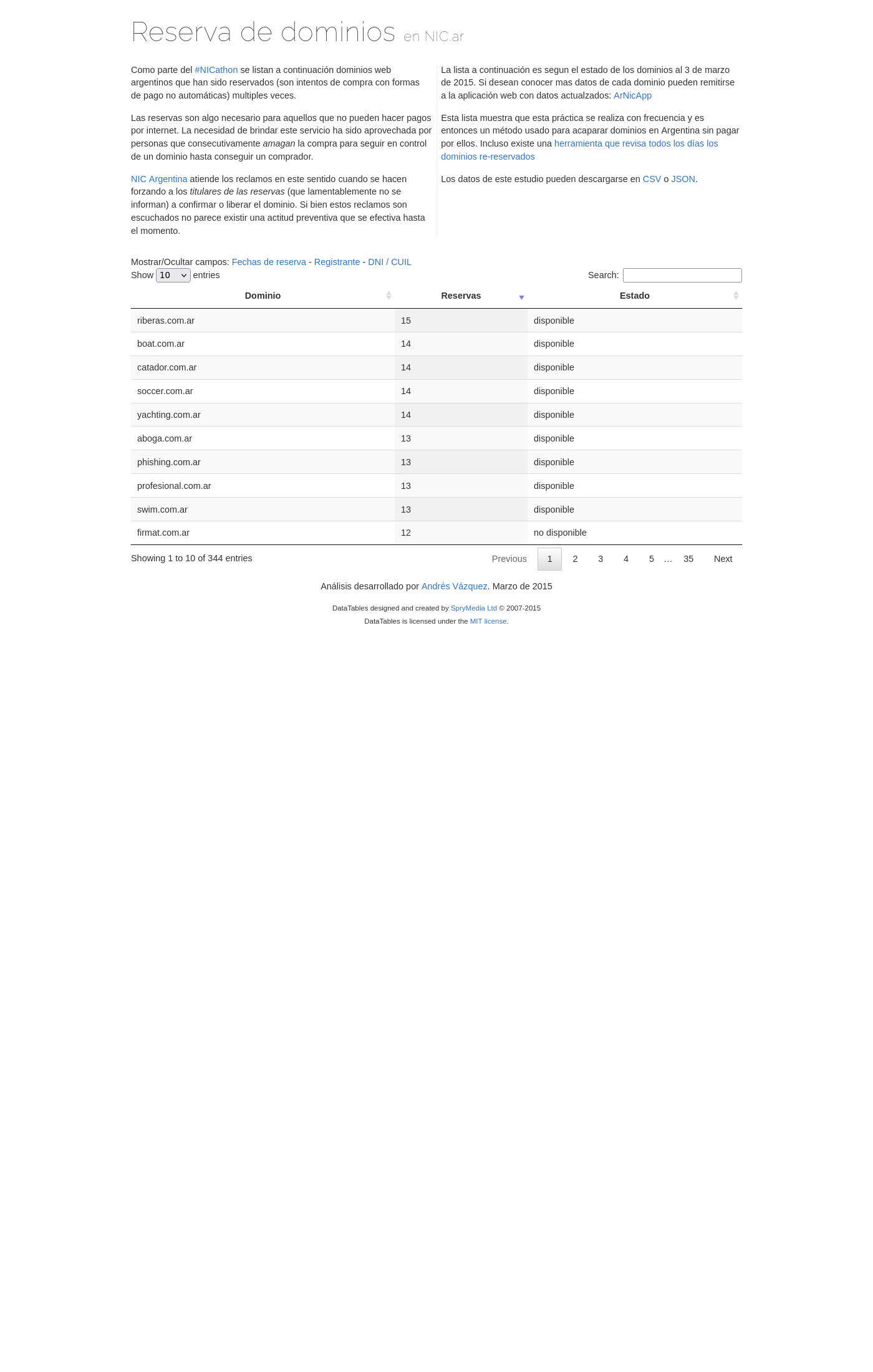
Masiva renovación de dominios en NIC
Análisis presentado durante el NICathon (marzo 2015).
Pago por primera vez de dominios en NIC.ar
El pasado 5 de marzo de 2014 NIC Argentina comenzo a cobrar por el uso de los dominios en la zona .AR. Esto fue avisado con tiempo y muchos registrantes tomaron posturas diferentes frente al cobro.
Algunas personas decidieron dejar de usar estos dominios y pasarse -por ejemplo- a dominios .com, otros continuaron con sus dominios argentinos pero hubo un tercer grupo que decidió prorogar lo más posible la posesión de sus dominios AR en modo gratuito.
Pongamos el siguiente ejemplo, usted usa 10 dominios en la zona .com.ar y vencen el 5 de abril de 2014. ¿No estaría tentado de dar de baja cada dominio (antes del 5 de marzo) y volver registrarlo para ahorrarse 11 meses de pago? ¿Y si usted fuera titular de 100 dominios? ¿Y de 1000?
Hasta aquí son especulaciones, veamos el gráfico Dominios registrados por día en 2014 (datos).
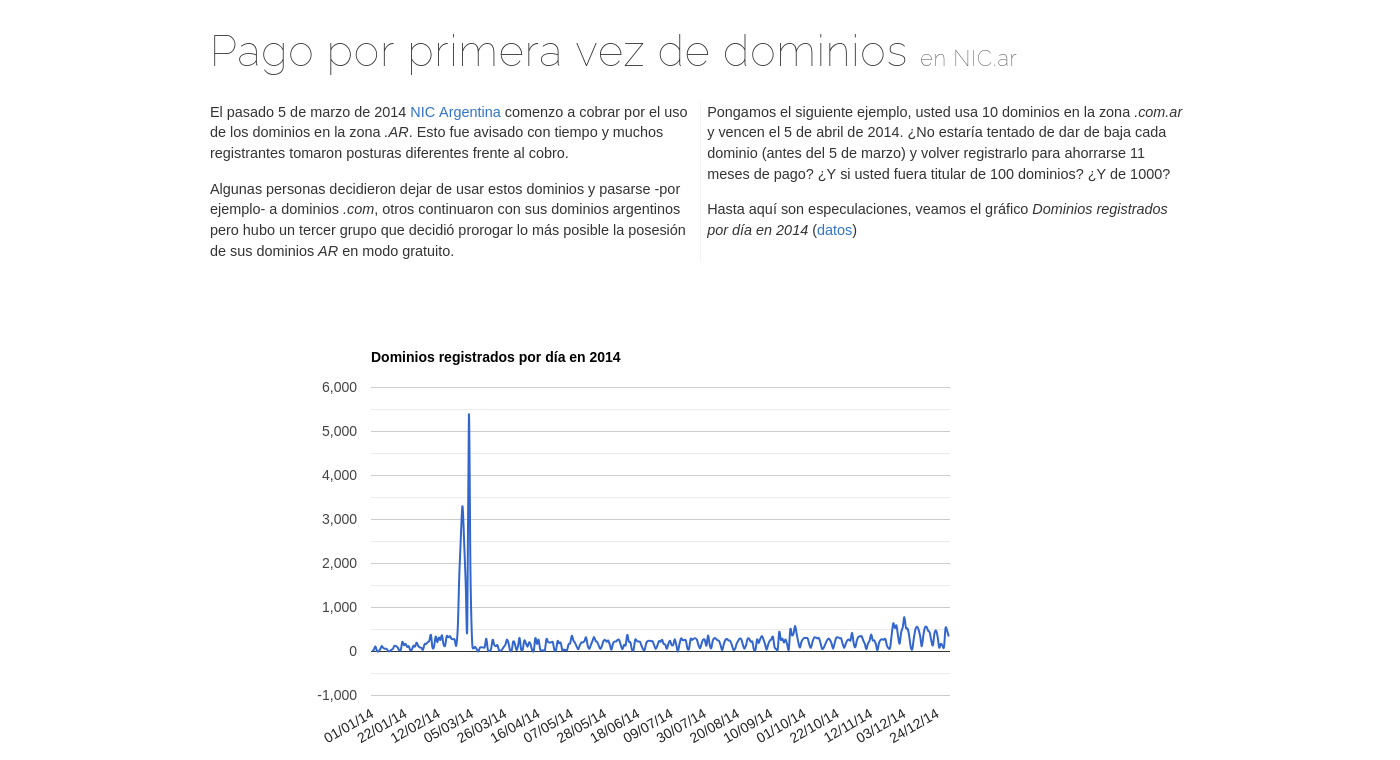
Está claro, algo paso en esos días previos a la fecha de pago. Pensemos ahora nuevamente en los administradores masivos de dominios, aquellos que deseaban extender un poco más sus dominios en versión gratuita. Con los datos liberados desde en el #NICathon se puede saber si los dominios registrados en esta fecha estaban registrados previo a ese registro, o sea, se re-registraron.
Los datos filtrados incluyen todos los dominios registrados entre el 24 de febrero y el 4 de marzo de 2014. Son mas de 11.000 dominios. El total de dominios en la base registrados en esa fecha es de 20.000. Se puede decir que la mitad de los dominios registrados en ese período no fueron nuevos registros sino cambios de fecha.
Vale la pena aclarar que la base de datos no es la totalidad de dominios en NIC, es solo una parte relevada por OpenDataCordoba.
Ahora, estos 11.000 dominios que se actualizaron tienen registrantes. ¿Quienes fueron?
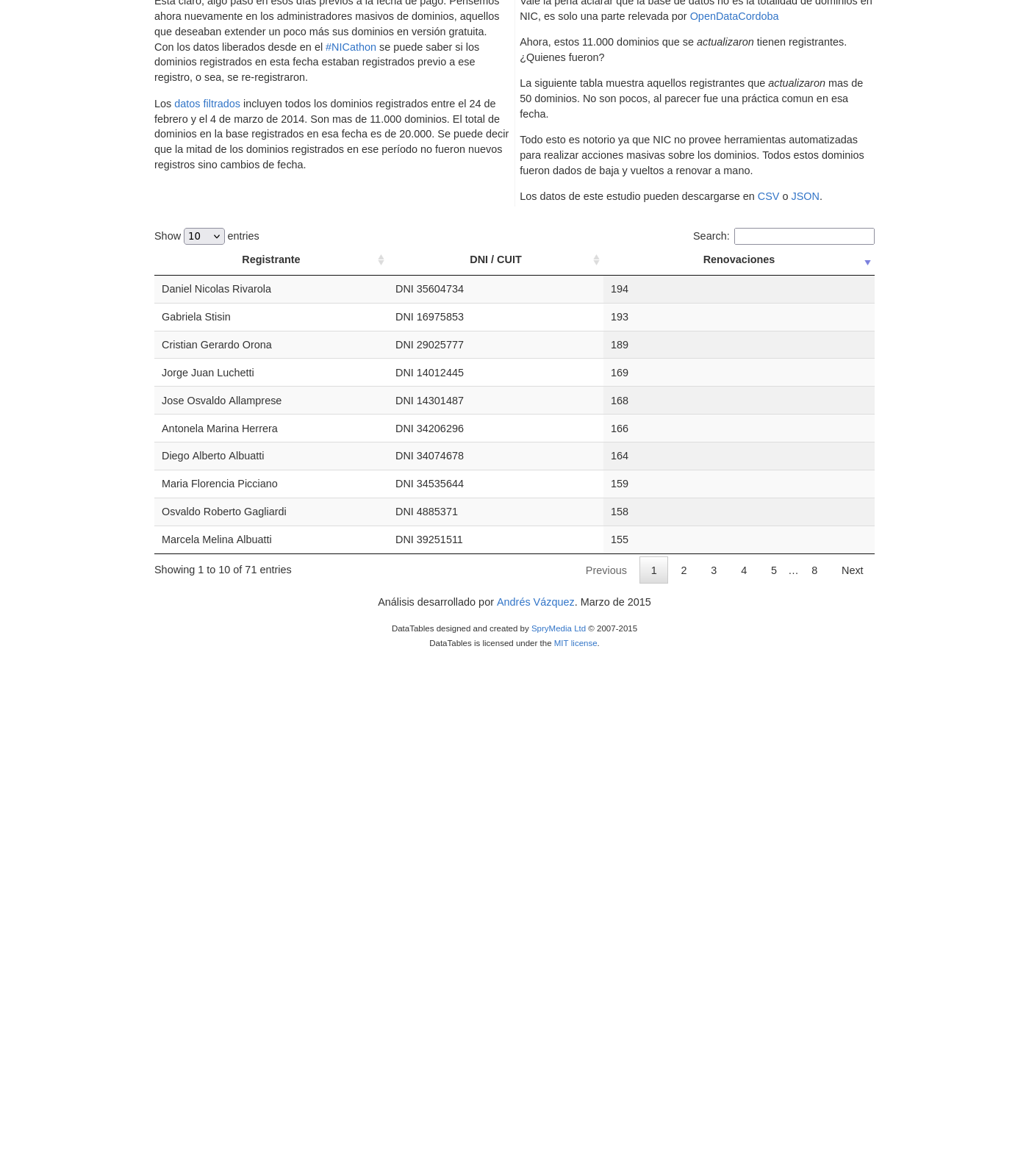
La siguiente tabla muestra aquellos registrantes que actualizaron mas de 50 dominios. No son pocos, al parecer fue una práctica comun en esa fecha.
Todo esto es notorio ya que NIC no provee herramientas automatizadas para realizar acciones masivas sobre los dominios. Todos estos dominios fueron dados de baja y vueltos a renovar a mano.
Visualización interactiva: /data/Masiva-renovacion-de-dominios-en-NIC/